Movie Review with Vector Representations
Majority of data is expressed as text format such as news articles, SNS and speech. Each article has some meanings and opinions, which have significant effects on things around us like economics, politics, etc. Therefore, using these information for prediction systems is important. Most of prediction algorithms, however, take input in the form of tensor (1st-order tensor is vector), which requires us to represent text data in the tensor(vector) form. In this article, we review popular three vector representation: Bag or Words, Word2Vec, and Doc2Vec. Then, we compare these qualities through sentiment analysis for movie reviews of IMDb. Then, we conclude that Doc2Vec is an efficient representation.
1. Vector Representations¶
We shall here introduce three of the most popular methods: Bag of Words, Word2Vec, and Doc2Vec.
Bag of Words¶
Bag of words is one of the most simplifying representations. We just count how many words we see in the text and represent as a vector whose components are the count numbers. Consider the case where we have the following two sentences:
- I like playing tennis. Kardashian likes playing tennis as much as I do.
- Kardashian actually likes playing baseball better than tennis.
Then, we have the following words list:
["I", "playing", "tennis", "Kardashian", "likes", "like", "as",
"much", "do", "actually", "baseball", "better", "than"]
Base on this words list, we obtain
- [2, 2, 2, 1, 1, 1, 2, 1, 1, 0, 0, 0, 0]
- [0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1]
Each i-th component of above vectors corresponds to the count number of i-th word in the word list; e.g., we have 2 at third component of the vector 1 and 1 at the vector 2 because we see ‘tennis’ twice in the first sentence and once in the second sentence. Though this representation is clearly oversimplification, it has been popular because of good performance.
We here treat different length sentences. The above representation leads to that the longer sentences we express, the bigger components. Therefore, we have to normalize vectors. Let $\bf{v}$ be a vector and let $v_i$ be its i-th component. We have $$ \tilde{v}_i = \frac{v_i}{\|\bf{v}\|}, $$ where $\|\cdot\|$ is some norm; e.g., L2 norm.
Word2Vec¶
The bag of words is oversimplified representation, which neglect the context. Next, we consider the another vector representation: skip-gram and continuous bag of words (CBOW) model, which has been introduced by T. Mikolov et al. in the paper. The main idea is estimating the meaning of each word from neighbor words. We assume the relation as in the below figure:
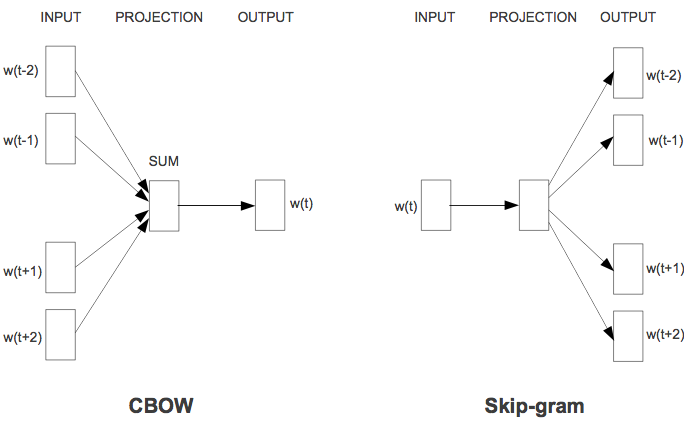
This figure comes from the same paper by T. Mikolov et al. While the current word vector is determined by the summation of forward and backward word vectors in CBOW model, the certain range forward and backward word vectors are determined by the current word vector in skip-gram model. Both models use log linear model to reduce the computational complexity by getting rid of non-linear hidden layer. T. Mikolov et al. has also introduced negative sampling to learn the skip-gram model efficiently in the paper.
These algorithms succeeded to extract linear feature. For instance, we denote by $vec[\cdot]$ a vector representation of a word. Then, we have the the following result: $$vec[king] - vec[man] + vec[woman] \approx vec[queen].$$ We can say that these algorithms are succeeded to find an effective representation of words in a vector space.
Doc2Vec¶
In most of applications like sentiment analysis, we are required to extract features from one sentence or paragraph. Though the Word2Vec has succeeded to grab semantic features of each word, they have poor performance when converting features of words into those of a paragraph through average over a document or CNN. As a sort of extensions, Q. Le and T. Mikolov have developed Doc2Vec, which extract features from various length one sentence or paragraph and produces fixed-length feature representation. In the paper, they have introduced two kind vector representations: Distributed Memory version of Paragraph Vectors (PV-DM) and Distributed Bag of Words version of Paragraph Vectors (PV-DBOW).
PV-DM simply adds one feature vector to CBOW model. The below figure explains the model architecture (cited from the original paper).
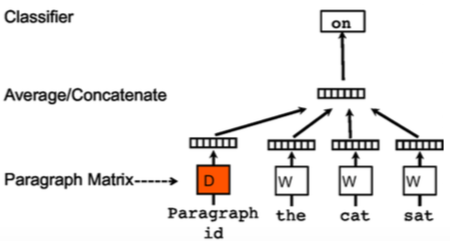
At the training stage, weight parameters for words and paragraphs are learned in the same way as Word2Vec. Note that weight parameters for words are shared across all of the documents while weight parameters for each paragraph is used only for one paragraph. At the prediction time after training, we fix weight parameters for classifier layer and words. Then, we learn the weight parameters for unseen paragraph.
PV-DBOW, on the other hand, extract features of a paragraph through optimization with sampled words, which is close to skip-gram model. The below figure explains the model architecture (cited from the original paper).
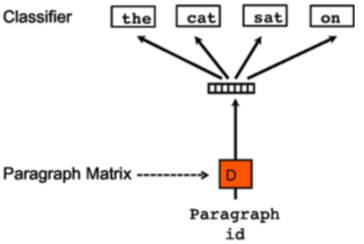
This model ignores the context and omit necessity to memorize weight parameters for words. At training time, we sample the text window and words from chosen text window. Then, we optimize parameters through stochastic gradient decent.
Empirically, taking concatenation of both vector representations gives better performance.
2. Experiments¶
In this section, we compare quality of vector representations introduced in the previous section. We use IMDb review data fetched from http://ai.stanford.edu/~amaas/data/sentiment. This data contains 100000 review, which can be divided into two folds: 50000 labeled and 50000 unlabeled reviews. The labeled reviews is able to split further into 25000 positive reviews scored from 7 to 10 out of 10 and 25000 negative reviews scored from 1 to 4 out of 10. Unlabeled reviews do not have any scores. We use half labeled reviews, 25000 reviews, consisting of 12500 positive and 12500 negative for train data and the other half for test data. Unlabeled data is used for unsupervised training of Word2Vec and Doc2Vec. In this experiment, we work on a binary classification problem to predict if unseen data is classified to positive or negative.
For implementation of Word2Vec and Doc2Vec, we use the python package, gensim, which contains various implemented methods for natural language process.
Let’s work on experiments while seeing an example of implementation of Doc2Vec. First of all, we have to load text data in the form of one of the classes of implemented at gensim.models.doc2vec, TaggedDocument, which has two attributes: words and tags. Words and tags have to be lists of strings. Note that we have to assign unique tag for each document; otherwise, we end up replacing old data with new data when they have the same tag.
When loading data, we set two parameters: ‘remove_stopwords’ and ‘remove_special’. Roughly speaking, stop words are frequent words with unimportant meanings; e.g., a, the, and you. Getting rid of these words often improve the performance. In this experiments, we get rid of stop words for all three representation. ‘remove_special’ refers to if we use special characters such as ‘?’, ‘!’, and ‘,’. Since special characters are included in the paper introducing Doc2Vec, we set ‘remove_special = False’ only for Doc2Vec.
import numpy as np
import os
import re
from bs4 import BeautifulSoup
from gensim.models.doc2vec import TaggedDocument
from nltk.corpus import stopwords
from six.moves import xrange, zip, map, filter
def get_document(file_dirs, remove_stopwords=True, remove_special=True):
documents = []
labels=[]
tags = []
for file_dir in file_dirs:
name_list = [x for x in os.listdir(file_dir) if '.txt' in x]
for x in iter(name_list):
# data is named as id_star.txt
comp_re = re.compile('(\d+)_(\d+).txt')
obj = comp_re.search(x)
f = open(os.path.join(file_dir, x), 'r')
# convert HTML format data to text data
review_text = BeautifulSoup(f.read(), 'lxml').get_text()
review_text = review_text.lower()
# get rid of special characters
if remove_special:
wordlist = re.findall(r"[a-z]+ | [^ a-z]", review_text)
else:
wordlist = re.sub("[^a-z]"," ", review_text).split()
# get rid of stop words; e.g., he, she, you, ...
if remove_stopwords:
stops = set(stopwords.words("english"))
wordlist = [w for w in wordlist if not w in stops]
# tag for each document
tag = "SENT_" + obj.group(1) + '_' + obj.group(2)
documents.append(TaggedDocument(words=wordlist, tags=[tag]))
f.close()
# seperate data into positive and negative
star = float(obj.group(2))
if star > 5:
labels.append(1)
else:
labels.append(0)
return [documents, labels, tags]
train_labeled = get_document(['./aclImdb/train/pos', './aclImdb/train/neg'],
remove_stopwords=True, remove_special=False)
train_unlabeled = get_document(['./aclImdb/train/unsup'],
remove_stopwords=True, remove_special=False)
test_data = get_document(['./aclImdb/test/pos', './aclImdb/test/neg'])
Using both unlabeled and labeled data, we extract features for each document. As in the original paper, we set dimension 400 for both of PV-DM and PV-DBOW and concatenate them; i.e., we have (75000, 800) for training.
from gensim.models.doc2vec import Doc2Vec
pvdm = Doc2Vec(train_labeled[0] + train_unlabeled[0], size=400, dm=1,
window=5, min_count=5, workers=4, max_vocab_size=50000, iter=11)
pvdbow = Doc2Vec(train_labeled[0] + train_unlabeled[0], size=400, dm=0,
window=5, min_count=5, workers=4, max_vocab_size=50000, iter=11)
After training, we can get vector for paragraphs by attribute, 'infer_vector'
def get_vectors(doc2vec, sentences):
return np.array(list(map(lambda x: doc2vec.infer_vector(x.words), sentences)))
# get paragraph vectors for training
train_pvdm = get_vectors(pvdm, train_labeled[0])
train_pvdbow = get_vectors(pvdbow, train_labeled[0])
train_paragraph = np.concatenate((train_pvdm, train_pvdbow), axis=1)
# get paragraph vectors for prediction
test_pvdm = get_vectors(pvdm, test_data[0])
test_pvdbow = get_vectors(pvdbow, test_data[0])
test_paragraph = np.concatenate((test_pvdm, test_pvdbow), axis=1)
Note that though we extracted the features through method 'infer_vector', we can also get features by 'pvdm(pvdbow).docvecs.doctag_syn0'. Since obtaining features through ‘infer_vector’ leads to better performance, we employed ‘infer_vector’ for both of training and test.
Now, we work on Logistic Regression with keras.
from keras.layers import Dense
from keras.optimizers import Adam
model = Sequential()
model.add(Dense(1, activation='sigmoid', name='output', input_shape=[800]))
opt = Adam(lr=1e-3)
model.compile(loss='binary_crossentropy', optimizer=opt, metrics=['acc'])
model.fit(train_paragraph, train_labeled[1], nb_epoch=100, batch_size=1000, verbose=2)
prediction = model.predict_classes(test_paragraph)[:, 0]
Here is the result:
| BOW | Word2Vec | Doc2Vec | |
|---|---|---|---|
| Accuracy | 86.6% | 84.3% | 87.5% |
3. Discussion¶
In this article, we have reviewed three vector representation of documents and compare their qualities as features of logistic regression. One of the benefits of Doc2Vec does not require high dimensional parameter space unlike BOW. For example, while Doc2Vec has 800 dimensional features in the experiment, BOW results in 5000 dimensional features to keep the quality. Besides that, Doc2Vec resulted in the best performance in the experiment.
We have implemented logistic regression through deep learning framework library ‘keras’, which makes it easy to extend logistic regression to multiple layer neural network by adding some layers. In the paper of Doc2Vec, by adding hidden layer with 50 units, they achieved 92.6% accuracy, which is far from our results. (By adding hidden layer with some regularization like batch normalization and dropout, we could not achieve this accuracy in the experiment). Since we did not choose hyper parameters with validation, we have possibilities need to improve the qualities of vectors with better hyper parameters.
As a feature work, by combining state-of-art deep learning algorithm after Doc2Vec layer, we can improve the performance more.